Retrospective on the Issue of Deletion of Withdrawal Member Records for ISMS-P Certification
Lee Youngsu|2026년 1월 25일|12분 읽기
Currently, our company is busy with various security tasks as we work to obtain ISMS-P certification. Among them, I am handling the issue of processing records of withdrawn members for our team's service.
Technically, it is called the right to be forgotten. - Right to erasure
There were other issues as well, but I took this on thinking it was an opportunity to learn Kafka. However, I realized that the issue is not as simple as I had anticipated...
I was assigned the issue around mid-December and am still working on it.
Accordingly, some content may be subject to modification.
This post unfolds the content using the introduction, climax, and resolution structure, summarizing the problem definition and the reasons for the challenges encountered.
Introduction
Change in Data Structure
It was not just about implementing the logic of deleting records. A system had to be built.
Our service's data had roughly three major issues.
- Change in data structure
In the past, specific requests were stored as:
"inputImageUrl" : ...Other requests were stored as:
"imageUrl" : ...Yet other requests were stored as:
"url" : ...Such forms had issues with adding the input, image as a requirement, and different structures being managed differently. Therefore, I received the issue of improving the structure in an array form and proceeded with it.
The latest data is stored as:
"inputFileList": [
{
"key": "...",
"url": "...",
"bucket": "...",
"inputFileType": "originalImage"
}
]Thus, the gap between the two structures had to be resolved.
Too Many Features
Currently, we have 18 features. (image-to-image, text-to-image, upscale, outpaint, remove-background ...) And each feature is composed in a Feature for creating requests and a Task for processing the request results.
All these features had to be guaranteed to work well...
Besides that,
- In some places, a Cloudfront URL is stored instead of an S3 URL.
- Old data is stored not in the form of s3 bucket, key, url but as url only.
- Some specific S3 URLs are used jointly and must be filtered to avoid removal.
Various data-related demands were hidden...
Data Scale
When we found the most requested user, they had made about 25,000 to 28,000 requests. Additionally, some requests would process and display 4 images.
client table - feature table - task table
The structure and all S3 URLs that emerge from each feature had to be neatly processed. And as time passes, the amount of data per user will eventually increase.
Processing all this data at once risks placing 50,000 entries into the DB upfront, causing load, or triggering an S3 Rate Limit.
These points required wise batch processing rather than processing everything at once.
Climax
Establishment of Interface
To solve issues 1 (long-standing data consistency) and 2 (too many features), interfaces were actively used.
We only had abstract FeatureEntity, TaskEntity, ResultEntity interfaces, but separately created interfaces related to taking input file data and providing generated file data per layer.
FileInputEntity, FileGenerateTaskEntity, FileGenerateResult
public interface FileInputEntity extends FeatureEntity {
List<InputFileInfo> getInputFileList();
}public interface FileInputOption {
List<InputFileInfo> getInputFileList();
}public interface FileGenerateTaskEntity<T extends FileGenerateResult> extends TaskEntity {
List<GenerateFileInfo> getGenerateFileList();
}public interface FileGenerateResult extends AIGenerateResult {
List<GenerateFileInfo> getFileList();Then, grouped the previous requests' values into this array.
@Override
public List<InputFileInfo> getInputFileList() {
if (CollectionUtils.isEmpty(inputFileList)) {
var files = new ArrayList<InputFileInfo>();
if (StringUtils.hasText(inputImageUrl)) {
files.add(
InputFileInfo.builder(
.key(key)
.bucket(bucket)
.url(url)
.inputFileType(InputFileType.ORIGINAL_IMAGE)
.build()
);
}
return files;
}
return inputFileList;
}@Override
public List<GenerateFileInfo> getFileList() {
if (CollectionUtils.isEmpty(fileList)) {
var list = new ArrayList<GenerateFileInfo>();
if (StringUtils.hasText(url)) {
list.add(GenerateFileInfo.builder()
.url(url)
.type(GenerateFileType.RESULT_IMAGE)
.mimeType(extension.getMimeTypeString())
.build());
}
if (StringUtils.hasText(webpUrl)) {
list.add(GenerateFileInfo.builder()
.url(webpUrl)
.type(GenerateFileType.RESULT_IMAGE)
.mimeType(FileExtension.WEBP.getMimeTypeString())
.build());
}
}
return fileList;
}Through this, the response format between previous data and current data was guaranteed to be identical.
Structural Design
Firstly, Kafka was used. To briefly explain the reason:
- We want to process it at a designated time.
There was potential for both logical and data-related load on the DB and our service. Some Features and Tasks are storing long Prompts, so even if you fetch 1000, the data turns out bigger than expected.
Possible room for improvement...
Due to these reasons, it had to run slowly at dawn when there were no user peaks.
+ As long as processing is guaranteed without requiring immediate real-time fast processing.
- Ensure that requests for the same user are processed by only one server.
Currently, there are not many API servers, but I disliked that such logic might impact if the number of servers increases.
Locks are usually used to prevent processing requests from the same user at the same time.
Whether it's a DB lock or a Redis lock.
However, I thought a lock was unnecessary in this method. It seemed it would create unnecessary contention.
Kafka allows specifying a Key when inserting messages.
If there are multiple partitions, the partition is determined based on this Key value.
-> There is no possibility of entering different partitions with the same Key.
And one server takes only one partition to process messages.
It was thought that a lock's equivalent effect could be expected without using a lock.
It is also advantageous for scaling, expanding the number of partitions increases the basic handling capacity.
Conclusively, to handle and process withdrawal data of our service, which has a decent number of users, the backpressure and - throughput is
...
Request generates a Kafka message
-> Receives and processes Kafka message at designated time
-> Stops receiving Kafka messages when the designated time is up
For this, the batch processing method:
- After querying the client table, group by request type
Map<String, List<ClientInfo>> clientInfoByAiGenerateType = clientInfoList.stream()
.collect(Collectors.groupingBy(
ClientInfo::getType,
Collectors.mapping(Function.identity(), Collectors.toList())));Our data structure judged it unlikely to go over 100,000 items yet, and as it consists of about 6 VARCHAR columns, deemed there was no issue.
- Batch processing by type
for (var entry : clientInfoByAiGenerateType.entrySet()) {
var resultInTypeBatch = processBatchInType(event.getRequestId(), entry.getKey(), entry.getValue());
deletionResult = deletionResult.addResult(resultInTypeBatch);
}private DeletionResult processBatchInType(
UUID requestId,
String type,
List<ClientInfo> clientInfoList
) {
DeletionResult deletionResult = DeletionResult.EMPTY;
log.info("{} type deletion start. requestId: {} | amount: {}", type, requestId, clientInfoList.size());
List<BatchRange> batchRangeList = BatchRange.split(clientInfoList.size(), BATCH_SIZE);
for (BatchRange range : batchRangeList) {
log.info("{} type deletion {} batch start. requestId: {} | amount: {}", type, range.index() + 1, requestId, range.size());
List<ClientInfo> batchClientInfoIds = clientInfoList.subList(range.start(), range.end());
DeletionResult batchResult = processSingleBatch(
requestId,
type,
batchClientInfoIds
);
deletionResult = deletionResult.addResult(batchResult);
log.info("{} type deletion {} batch completed. requestId: {} | completed result: {}", type, range.index() + 1, requestId, batchResult);
}
log.info("{} type deletion complete. requestId: {} | result: {}", type, requestId, deletionResult);
return deletionResult;
}- Create an empty result
- Work segmentation as per desired amount - BatchRange
- Batch processing
- Add result
Thought through processing in batches in some depth
private DeletionResult processSingleBatch(
UUID requestId,
String type,
List<ClientInfo> batchItem
) {
// 1. Query (No transaction)
ErasureTarget targets = deletionDataService.findDeletionTargets(requestId, type, batchItem);
// 2. S3 deletion (No transaction)
int s3DeleteCount = s3DeletionService.deleteFiles(targets.getS3Files());
// 3. DB erasure (With transaction)
ErasureResult dbResult = deletionDataService.executeDbDeletion(requestId, targets);
return DeletionResult.builder()
.featureCount(dbResult.featureCount())
.taskCount(dbResult.taskCount())
.s3FileCount(s3DeleteCount)
.build();
}Progressed with the code flow as above.
- Fetch necessary data from DB
- Tag marking or direct deletion based on S3 info
- DB data erasure
S3 data was seen as most critical.
- Once processed in the DB, it becomes impossible to trace which request created a specific S3 object
- S3, when requested with a non-existent file, either informs with
No Such ...or processes as is
This ensured that processing of S3 files is guaranteed, and deemed irrelevant to have multiple requests sent.
Consequently, omitted declaring transactions during S3 processing.
Resolution?
Thought I roughly wrote down the flow of the code.
Hence, asked AI to create a script to test this flow for validation.
However, upon review and while opening actual operational data, realized there were issues.
Back to Introduction-Climax...
The following content addresses issues specific to our team.
Client Table Consistency Issue
Our team has an entity called client used to identify every request. (such as which client key made a request and so on)
This table accumulates data, and as simple indexing has its limits, it was partitioned as necessary.
During this, our old client table lacked created_at.
To solve this, we created a new table with created_at and partitioning applied from the start.
Nevertheless, the old requests of users also had to be erased.
The issue was the consistency that had to be matched due to old tables, naturally.
public class CustomClientInfoRepository {
/**
* Retrieve all data with the given clientKey from legacy tables (temp, old)
*/
public List<ClientInfo> findAllByClientKey(String clientKey) {
List<ClientInfo> allResults = new ArrayList<>();
// Combine results retrieved from both tables
allResults.addAll(selectList(SELECT_CLIENT_OLD_SQL, clientKey, CLIENT_OLD_TABLE));
allResults.addAll(selectList(SELECT_CLIENT_TEMP_SQL, clientKey, CLIENT_TEMP_TABLE));
allResults.addAll(clientInfoRepository.findAllByClientKey(clientKey));
return allResults;
}private static final String SELECT_CLIENT_OLD_SQL = """
SELECT * FROM client_old
WHERE client_key = :clientKey
""";Created CustomXXXRepository to process the request without outsiders knowing it's from the old tables.
Expanding Capabilities for Other Features
Initially, I handled AIGenerate Feature deletion.
However, there was also a service extracting text and image data from PDFs! 🫠
To reflect, the reason this was overlooked could be:
/**
* Image generation request type
*/
@Getter
public enum AIGenerateType {
/**
* Text-to-image request type
*/
TEXT_TO_IMAGE,
/**
* Image-to-image request type
*/
IMAGE_TO_IMAGE,
...
}We were managing all request types within this ENUM.
Additionally, I handled modules not related to PDFs, so the impact scope was not properly identified.
An extension in existing code became necessary.
private final List<AIGenerateEntityErasureRepository> erasureRepositories;
@Override
public ClientErasureDataService.DeletionTargets findDeletionTargets(String type, List<ClientInfo> clientInfoList) {
var aiGenerateType = AIGenerateType.findByAlias(type);
var repository = findRepository(aiGenerateType);
...
}
private AIGenerateEntityErasureRepository findRepository(AIGenerateType type) {
return erasureRepositories.stream()
.filter(repo -> repo.getAIGenerateType() == type)
.findFirst()
.orElseThrow(() -> new IllegalArgumentException("Repository not found: " + type));
}
public interface AIGenerateEntityErasureRepository {
/**
* Returns the AIGenerateType handled by the Repository
*/
AIGenerateType getAIGenerateType();
...
}The existing code was written assuming AIGenerateType was coming in, and PDFs lack AIGenerateType.
Additionally, PDF result creation is somewhat different from AIGenerate.
PDF extraction results can create up to 1000 images per outcome.
Hence, they do not store in a fileList or any other variable, but rather store the fileKeyList within the JSON. (DB contains only the JSON path)
Thus, must retrieve from S3 JSON first -> next assemble fileKeyList to return it.
=> Accordingly, created a Handler at a higher layer.
public interface ErasureHandler {
boolean supports(String type);
DeletionTargets findDeletionTargets(String type, List<ClientInfo> clientInfoList);
...
}An interface specifying whether the input type is processable and how it should be processed, implemented with
public class AIGenerateErasureHandler implements ErasureHandler {
...
}public class PdfErasureHandler implements ErasureHandler {
...
}implemented the two. The pros of this structure as I see them are:
- When AIGenerateType increases, the scope of interest doesn't spread.
Given our service structure, there is considerable potential for more features.
(AI features and workflows utilizing AI features can emerge, thus new features can be generated by wrapping them.)
Whenever this happens, adding just a Repository will naturally let AIGenerateErasureHandler handle it.
Instead of implementing handlers for each feature,
It's divisions like AIGenerate/PDF/...
Conclusion
I provided AI with thinkers on my validated test cases based on this implementation.
-
Does the erasure apply well to all AI features?
-
Does erasure apply well to PDF elements?
-
In case option has only s3 url
-
In case option has only cf url
-
In case option has bucket, key, cf url
-
In case option has bucket, key, s3 url
-
In case inputFileList in the option has values - guarantees keys, buckets within the array
-
In case result has only url variable
-
In case result has fileList
Constructed a script based on conversation with AI to verify and practically tests it.
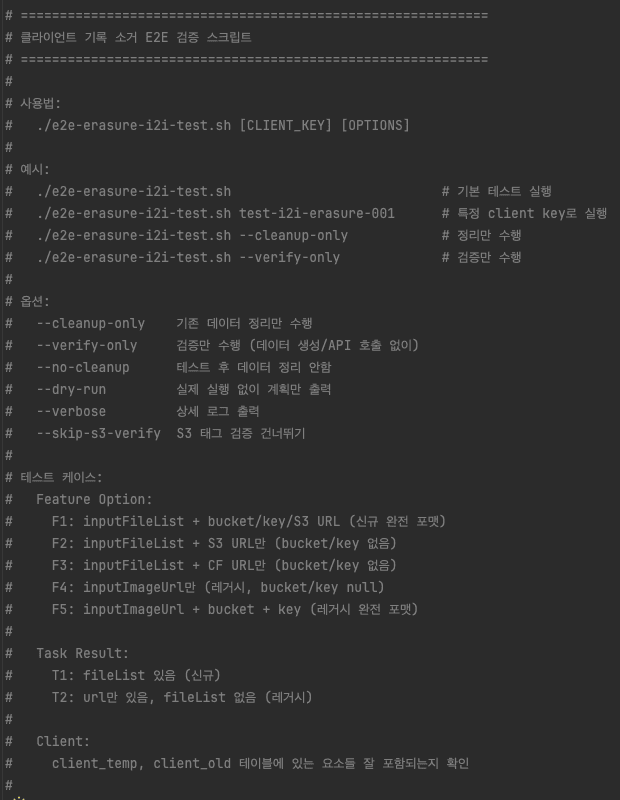
Conclusion
This issue brought some realizations, hence summarizing them here.
Importance of Data Understanding
Code is ultimately subject to maintenance.
Whether it's refactoring or changes and improvements made as needed, it gets continually modified.
However, data can be somewhat different.
Ideally aligning the data consistently with the code is not always possible.
EX) Consider 20 million records accumulated under a url variable.
Now, if values are to be put into a fileList, what should happen to the old url variables?
- A one-time execution via a flyway script.
- Match the old data consistency through batch work. (Technically known as backfill)
- Leave them as is. ☠️
Aligning data consistency can be unexpectedly cumbersome.
Performing Updates on an operational DB disrupts the fast deployment cycle. (how to configure backfill..? rollback the data structure..?)
Such states of data overlap can exist.
They might not be evident in the code.
Variable disappeared, variable name changed, a variable thought never to become null might become null...
If you ever have to deal with the whole table, trace back data statuses as you follow the commit history.
Failing to consider this initially while writing code can lead to numerous defensive codes or unforeseen errors popping up everywhere.
Interface is Good
Honestly, I didn't quite feel confident about using interfaces until now.
But I think I used interfaces quite satisfactorily in this issue.
The trait of this issue was its unexpectedly large extent of work.
If implementation direction, data structure change, testing, code quality, etc., were all tried to be done together, the issue would have significantly been bottlenecked by single processing.
(Our team requires review from 3 people before merging.)
Interfaces helped segment the work ambit nicely.
- An interface for bridging the gap between long-existing data and current data structure
- Interfaces defining necessary methods across 18 features and an abstract class to remove duplicate codes
- A unit of work division interfaces like AIGenerate, PDF...
The biggest advantage was not breaking the context for reviewers viewing the code in PR.
When encompassing the whole issue content, adjustments due to existing code flaws are bound to exist.
However, while seeing important content, a 'minor revision' here can disrupt concentration.
They can see with ease, guided by an interface declared. - implementing an interface.
And it allows gleaning how this interface will be used, an early hint to the direction of the next code.
- Imposing constraints on future code convention
- Providing a guideline to the direction of the next code
- Separation of concerns in review
@Override
public DeletionTargets findDeletionTargets(String type, List<Long> clientIdList) {
var aiGenerateType = AIGenerateType.findByAlias(type);
AIGenerateEntityErasureRepository repository = findRepository(aiGenerateType);
var features = repository.findFeatureByClientIds(clientIdList);
...
return new DeletionTargets(...);
}If deletion data returning logic as above exists,
I implemented 18 repositories, irrelevant to how Repository was implemented.
Only how it should be used in the structure by implementing declarations matters.
Everything Is a Trade-off
This was something I realized while developing within the company, but felt again now.
Even down to tiny parts of code, the trade-off domain approaches.
To illustrate an example,
- Handling the data, how?
- Process individually.
- Process in batch.
-> Since the data may be vast and would cause load, it must be processed in batch.
- If it fails during batch processing, how to handle?
- Rollback the Transactional and start afresh?
- Ignore failures and process?
- Retry once more?
- How should data be handled?
- Hard-Delete
- Soft-Delete
-> Although it's user record, when created & which GPU timeline is composed such data might be used,
Soft-Delete with only user record masking seems best.
- Upon setting NULL or
{}for data, any server logic issues? - Is the client-side code adapted to sudden evolving schemat?
- How to obtain record deletion requests from other teams?
- Simply open as an API?
- How to authenticate the requestor?
- Open with a back-office?
- Wouldn't it be cumbersome to do manually?
Perhaps, receiving the list of withdrawn users all at once, and our team doing it manually via Excel or providing a dedicated back-office might be more efficient.
- When a record deletion request responds with success, can it guarantee it's always processed as stated?
-> Just in case, if failures occur, considered saving records in DB and issuing Kafka messages ensuring re-processing capability.
- If Kafka message delivery fails, then what?
- If Kafka processing fails, how should DB change?
=> Ultimately, we have to weigh and choose endlessly.
AI provides answers (sometimes none)
We cannot discern what is the red pill, blue pill until chosen.
Conclusion
Though the work isn't fully completed, feeling pretty fulfilled seeing a big task handled by myself.
Handling differences between previous and existing data structures across 36 tables,
Processing maximum 25~28,000 requests & ~50,000 images per user in batches load-free,
Designed evolved future-proof architecture, whatever features added henceforth,
Tested, E2E verified & structurally processed this all thoroughly.
Here's hoping for further growth.
空