Threads and ThreadPools in Java
이영수|2025년 1월 17일|17분 읽기
This content was written while contemplating the question, "Why are multiple thread pools necessary?"
As it was written based on actual tests, there may be some inaccuracies.
If you find any mistakes, please let me know atjoyson5582@gmail.comor in the comments 🙂
Before organizing threads and thread pools in Java,
I'll start by understanding how threads work in the O.S.
This makes it easier to understand how to wisely manage and use threads and thread pools in Java.
Detailed explanations of concepts are not covered.
Threads in O.S
You've probably heard this often.
Threads are the workers within a process.
So how do these threads work well within our programs?
Hardware Threads
Computers have cores.
These cores are responsible for processing program instructions and performing calculations.
The number of cores is very small (4, 8, 16, etc.), so they must be processed very quickly and efficiently.
A core's dilemma: The time spent waiting for data from memory is quite long.
(Because the core is idle while doing memory-related work)
-> Let's have different tasks performed in each space that accesses memory!
=> Let's run different threads to avoid wasting time.
This is what hardware threads are.
-threading in Intel: Two hardware threads are assigned to each physical core.
- A virtual core from the O.S perspective
What if a single-core CPU has two hardware threads?
-> The O.S recognizes this CPU as a dual-core and performs O.S-level thread scheduling accordingly.
Kernel, O.S Threads
What is a Kernel?
It is the core of the operating system.
This term is not limited to Linux but applies to Windows, iOS, Linux, etc.
- Manages and supervises the entire system
- Directly performs hardware-related tasks
(I'll explain a bit more about why the kernel is necessary in the User Threads section below.)
O.S Threads
Threads created and managed at the kernel level.
(The actual unit of execution on the CPU; the unit of CPU scheduling is the O.S thread)
- O.S thread context switching involves the kernel -> incurs cost
- Both user code and kernel code are executed at the O.S thread level
What if we use elements like System Call in the code we write?
-> The OS Thread executes the kernel code.
-> It returns to user mode, and the code we wrote is executed.
They are also called:
Native threads
Kernel threads (can be used with different meanings depending on the context, e.g., a thread that performs the role of the O.S kernel)
Kernel-level threads
OS-level threads
User Threads
Related to User Programs (Java, Python, Go...)
They are called user-level threads.
It is an abstraction of the thread concept at the programming level.
Thread thread = new Thread();
thread.start();As shown, it's provided by the programming language.
If we look closer at thread.start,
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
private native void start0();start0 calls the O.S's System Call via JNI.
-> It calls a system function like clone to create one O.S-level thread (in Linux).
-> The O.S-level thread gets connected to the Java user thread.
- For a user thread to run on the CPU, it must be connected to an O.S thread. (More on this in the Model section below)
When a System Call is invoked
It switches from User Mode -> Kernel Mode.
- Save the program's current CPU state.
- The kernel directly handles the interrupt or system call (the CPU executes kernel code).
- When processing is complete, restore the CPU state of the interrupted program.
Control is returned, switching from Kernel Mode -> User Mode.
To protect the overall system
(Because it could lead to arbitrary hardware definitions and collapse of the entire system)
- Interrupt: A mechanism that informs about various types of events occurring in the system.
I/O operation completion, time-out, division by zero, accessing an invalid memory space, etc. (In Java, InterruptedException exists.)
-> The CPU immediately executes kernel code in kernel mode to handle the interrupt.
- System Call: Used when a program wants to use services provided by the OS kernel.
It's called for processes/threads, file I/O, sockets, inter-process communication, etc.
When called, the corresponding kernel code is executed in kernel mode.
CASE: File READ operation
Assume t1 performs a file read operation, and t2 performs another task.t1 calls the
ReadSystem Call and enters kernel mode.
- It changes to the WAITING state until the file is read.
- The CPU, through scheduling, changes t2 from READY -> RUNNING to operate.
It switches from kernel mode to user mode.While t2 is performing its task, the SSD (File System) generates an interrupt indicating the file is ready.
To handle the interrupt, it switches to kernel mode (saving the CPU state of the currently working t2).
- It changes t1 from WAITING -> READY.
It restores the CPU state of t2 and resumes its task.The timer generates an interrupt because the time slice has been used up.
To handle the interrupt, it switches to kernel mode (saving the CPU state of the currently working t2).
- t1 becomes READY -> RUNNING.
- t2 becomes READY.
So how are these user threads processed and managed?
This depends on the method designed by the programming language.
This is referred to as the ... Model.
One-To-One Model
This is the method used in Java. (Therefore, as explained, it must be connected to an O.S thread).
Thread management is delegated to the O.S, and scheduling is also performed by the kernel.
Since the O.S handles it, it utilizes multi-core well.
- Even if one thread is BLOCKED, other threads work fine (due to the 1:1 relationship).
-> A Race Condition can occur.
Many-To-One Model
N user threads: 1 O.S thread
It's related to coroutines - a coroutine is not a Many-To-One Model, but it can be used that way.
- Faster context switching (no kernel intervention, switching is handled at the application level).
- Almost no possibility of a Race Condition at the O.S level (occurs at the user level).
- Cannot utilize multi-core (as only one is active at a time).
- If the O.S thread is blocked, all user threads are blocked. (This is why Non-Blocking IO emerged).
Many-To-Many Model
N user threads: M O.S threads (where M <= N)
- A model that combines the advantages of the two models above.
- Even if an O.S thread is blocked, another O.S thread handles it.
- Implementation is complex. (Supported by Go).
Green Threads?
Early versions of Java are said to have used the Many-To-One threading model.
At that time, user threads were called green threads.
It has since been expanded and is now also used to mean threads scheduled at the user level, independent of the OS.
It's just something to be aware of.
Multitasking ⭐️
This part is continuously important.
It can be a fundamental approach to why a thread pool is needed.
The CPU has a constraint that only one process or thread can run at a time. (Assuming a single thread for now).
-> This is solved through multitasking.
A method of allocating a very short CPU time, and when that time is used up, the next thread runs.
(t1 -> t2 -> t3 -> t1 -> t2 -> ...)
The equally given CPU time is called a time slice or quantum (a few to tens of ms).
This slice is not fixed!
If the slice were fixed?
-> As the number of concurrently running threads increases, the waiting time for a thread to run and get its turn again becomes longer.
=> The time slice is adjusted according to the number of concurrently running threads. (CFS scheduler).
Currently, since Linux 6.6, it has been replaced by a scheduler called
eevdf.
https://www.reddit.com/r/linux_gaming/comments/17rohqp/linux_66_with_eevdf_the_new_cpu_scheduler_gaming/
CFS focuses on fairness, while EEVDF considers latency.
-> It removes complexity and lowers latency.
This content is explained based on CFS. (As it's not a topic to be dealt with in-depth from the perspective of Java - thread pools).
- target latency: The target time for a task to be allocated to the CPU.
- time slice: The time a task is in progress (the interval at which Context Switching occurs).
20ms + 4 tasks => time slice is 5ms
As the number of threads increases, context switching occurs more frequently.
Additionally, synchronization for shared resources inevitably occurs.
So, we know that more threads are not necessarily better, but does this apply to the application level?
Now, let's start with Threads in Java.
Threads in Java
As mentioned above, threads in Java have a 1:1 mapping with operating system-level threads (a wrapper for operating system threads).
This is not discussed from the
Virtual Threadperspective.
(Because there are still issues with pinning at thecarrier threadlevel and a lack of various use cases).
So, Java has the following characteristics:
- If you create an unlimited number of threads, resources will be exhausted very quickly - because it uses operating system resources.
- Creation and destruction take a long time - because it requires operating system-level management.
- It blocks when it encounters I/O operations - calls an Interrupt.
Therefore, a thread pool is needed to avoid creating unlimited threads + avoid continuous creation and deletion.
Threads - Thread Pool
A thread pool is literally a pool of threads.
It allows you to create threads in advance and take them out one by one when you need to use them.
How does a thread pool work in Java?
This is explained based on
ThreadPoolExecutorandAbstractExecutorService.
A thread pool operates in the following steps:
- A Task Submitter delivers a task to the Thread Pool. -
AbstractExecutorService.submit - The received task is stored sequentially in the Thread Pool's Queue. -
workQueue.offer - If an idle Thread exists, it takes a task from the Queue and processes it. -
ThreadPoolExecutor.getTask - If no idle Thread exists, it waits in the Queue until one is available.
- A Thread that has finished its task waits for a new task to arrive from the Queue.
Let's look at it with some code.
// AbstractExecutorService.submit
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}// ThreadPoolExecutor.execute
public void execute(Runnable command) {
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}-
If the number of worker threads is less than the core pool size?
-> Add a worker thread. -
If the thread pool is currently
RUNNING&& the offer to the work queue was successful?
-> If, upon rechecking, it's notRUNNING&& the removal from the work queue is successful? - Reject it.
-> If the number of worker threads is 0? - Add a worker thread. -
If adding a worker thread fails? - Reject it.
// ThreadPoolExecutor.addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
...
workers.add(w);
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
...
return workerStarted; // ThreadPoolExecutor.Worker
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}
private volatile ThreadFactory threadFactory;- A thread is created from the
ThreadFactoryand assigned to the worker. - A lock is acquired using
ReentrantLock. - It is added to the worker queue.
- Once added, the worker thread starts. - (1.
t.start()2.Worker.run3.ThreadPoolExecutor.runWorker)
// ThreadPoolExecutor.runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
try {
beforeExecute(wt, task);
try {
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}It gets a task and executes it.
It gets a task via firstTask or getTask() and runs it.
(The getTask() part is an interface.)
So, I understand that the thread pool continuously fetches and executes tasks.
So, what's the performance difference between using a thread pool and not using one?
Thread Pool Performance Comparison
The code can be found here.
Even though the tasks are bundled together, I measured them by running them one by one. (A very repetitive chore...)
On a MacBook, you can check this via Activity Monitor -> double-click a process -> Statistics -> Context Switches.
(In Linux, there is a tool called perf).
My MacBook is an M2 Air with 8 cores and 16GB of memory - for performance reference.
CPU Intensive
static class CpuMemoryIntensiveTask implements Runnable {
private static final int DATA_SIZE = 10_000; // 10KB memory
private static final int ITERATIONS = 9000000; // number of iterations
private static final Random RANDOM = new Random();
@Override
public void run() {
int[] data = new int[DATA_SIZE]; // create 10KB array
// store random values in the array
for (int i = 0; i < DATA_SIZE; i++) {
data[i] = RANDOM.nextInt();
}
// random memory access task
for (int i = 0; i < ITERATIONS; i++) {
int index = RANDOM.nextInt(DATA_SIZE);
data[index] = (int) (data[index] + Math.tan(data[index]));
}
}
}Large memory + RANDOM ACCESS
-> The memory cache needs to be cleared continuously.
-> CPU workload increases.
This allows us to compare performance for CPU-intensive tasks.
runWithThreadPool(4, 10); // Using thread pool
runWithoutThreadPool(10); // Creating threads directly without a pool
Execution Time (ThreadPool): 7799 ms
Execution Time (Without ThreadPool): 19487 msExecution Time (ThreadPool): 15250 ms
Execution Time (Without ThreadPool): 32587 msWorking without a thread pool takes longer.
pool-1-thread-3 running start : taskId : 4time : 1736945552855
pool-1-thread-1 finished : taskId : 0time : 1736945552869
pool-1-thread-1 running start : taskId : 5time : 1736945552869
pool-1-thread-2 finished : taskId : 1time : 1736945552888
pool-1-thread-2 running start : taskId : 6time : 1736945552888Thread-4 running start : taskId : 4time : 1736945565048
Thread-5 running start : taskId : 5time : 1736945565048
Thread-6 running start : taskId : 6time : 1736945565048
Thread-7 running start : taskId : 7time : 1736945565051
Thread-8 running start : taskId : 8time : 1736945565060
Thread-9 running start : taskId : 9time : 1736945565078
...Even though the logic running without a thread pool started almost simultaneously,
...
Thread-7 finished : taskId : 7time : 1736945597620
Thread-17 finished : taskId : 17time : 1736945597622
Thread-1 finished : taskId : 1time : 1736945597629
Thread-16 finished : taskId : 16time : 1736945597633You can see that the end times are uneven.
-> In other words, even if tasks are executed together, the time it takes for the CPU to execute them is inevitable.
runWithThreadPool(4, 30); // Using thread pool
runWithThreadPool(8, 30); // Using thread pool
runWithThreadPool(12, 30); // Using thread pool
Execution Time (ThreadPool): 22479 ms
Execution Time (ThreadPool): 70021 ms
Execution Time (ThreadPool): 68767 ms
Now, let's check if increasing the number of threads in the pool really doesn't reduce the time, as mentioned above.
runWithThreadPool(4, 30); // Using thread pool
runWithThreadPool(8, 30); // Using thread pool
runWithThreadPool(12, 30); // Using thread pool
Execution Time (ThreadPool): 22479 ms
Execution Time (ThreadPool): 70021 ms
Execution Time (ThreadPool): 68767 ms
...
Execution Time (ThreadPool): 22415 ms
Execution Time (ThreadPool): 56424 ms
Execution Time (ThreadPool): 54439 msOn the contrary, you can see that the time increases significantly.
Measuring how much CPU Context Switching occurred:
runWithThreadPool(4, 30) had 18,439 switches.
runWithThreadPool(8, 30) had 410,752 switches.
runWithoutThreadPool(20) had 401,040 switches.
This occurred.
-> This showed how much performance degradation can be caused by incorrect settings.
File IO
I implemented an IO task by creating a file, connecting to it, and writing content.
try (BufferedWriter writer = new BufferedWriter(new FileWriter(fileName))) {
for (int i = 0; i < 10000; i++) { // write 10000 lines to the file
writer.write("Task " + taskId + " - Line " + i + "
");
}
} catch (IOException e) {
e.printStackTrace();
}When the buffer is full, it automatically flushes to the file.
int taskCount = 2000;
runWithThreadPool(8, taskCount);
runWithThreadPool(100, taskCount);
runWithoutThreadPool(taskCount);
Execution Time (ThreadPool): 3821 ms
Execution Time (ThreadPool): 10966 ms
Execution Time (Without ThreadPool): 14274 ms
Naturally, since thread creation and destruction are not handled,
the thread pool is more efficient.
And, it uses very little CPU time.
Network IO
I get file IO, but what about network IO?
I'll approach this in two ways (requests that finish quickly, and requests that finish slowly).
URL url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000); // set connection timeout (5 seconds)
connection.setReadTimeout(5000); // set read timeout (5 seconds)This is how a network request is sent.
Fast-finishing requests
//final String urlStr = "https://jsonplaceholder.typicode.com/posts/1"; request
runWithThreadPool(8, taskCount);
runWithThreadPool(100, taskCount);
runWithoutThreadPool(taskCount);
Execution Time (ThreadPool): 1150 ms
Execution Time (ThreadPool): 774 ms
Execution Time (Without ThreadPool): 864 ms
Network IO also receives very little CPU time and has very few context switches.
Slow requests
Send a request to
https://httpbin.org/delay/2to process it.
If you send a request to this path, it will wait fordelay/{number}seconds before responding.
//final String urlStr = "https://httpbin.org/delay/2"; request
Execution Time (ThreadPool): 41596 ms
Execution Time (ThreadPool): 6000 ms
Execution Time (Without ThreadPool): 6445 ms
This is the result.
Even if it takes a long time, it doesn't affect the CPU.

The heap memory occupied by each differs.
From this, we can see that for IO tasks, heap memory and throughput are proportional.
And, we can also see that CPU Context Switching occurs relatively infrequently.
OOM
So, what if we reduce the number of threads in the pool to reduce heap memory, sacrificing some execution time?
As you can see from the title, this can actually cause an OOM.
int taskCount = Integer.MAX_VALUE; // number of tasks
runWithThreadPool(1, taskCount);If we intentionally create only one thread in the thread pool and put in 2.1 billion tasks?

It quickly exceeds the memory, and the CPU time and context switching are enormous.
pool-1-thread-1 running start : taskId : 6time : 1736990425896
pool-1-thread-1 running start : taskId : 7time : 1736990447620
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.base/java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:409)
at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1357)
at java.base/java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:123)
at joyson.threadpool.ThreadPoolDiffInNetworkIOIntensive.runWithThreadPool(ThreadPoolDiffInNetworkIOIntensive.java:29)
at joyson.threadpool.ThreadPoolDiffInNetworkIOIntensive.main(ThreadPoolDiffInNetworkIOIntensive.java:16)
pool-1-thread-1 running start : taskId : 8time : 1736990480824
pool-1-thread-1 running start : taskId : 9time : 1736990483422An OOM also occurs in the code.
What's interesting here is that even if an OOM occurs, the thread task still runs.
(I looked it up, and even if an OOM occurs in the OFFER part, other threads still process their tasks.)
ExecutorService threadPool = Executors.newFixedThreadPool(1);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}The default LinkedBlockingQueue accepts up to INTEGER.MAX_VALUE items in its queue.
Tasks are continuously added to the Queue without limit, consuming memory.
Therefore, you need to either adjust the number of threads to process them quickly or adjust the size of the queue.
Additionally, you can decide how to reject and handle requests when the queue is full - rejectedExecutionHandler.
I'll substitute this part with what I organized during a mission at Woowacourse. - Link to mission summary
Conclusion
- In most cases, not using a thread pool and only using threads is worse for performance. (System Call overhead + creation & destruction)
- For CPU-bound tasks, having more threads is actually worse. (Context Switching)
- For IO-bound tasks, it doesn't matter if there are many threads. (Most are
WAITINGuntil they receive an Interrupt) - The number of threads in a thread pool is proportional to the heap memory capacity.
- The number of threads and the queue size of a thread pool must be set appropriately.
Now, let's finally address the big question: Why are multiple thread pools necessary??
Why are multiple thread pools necessary?
I looked it up, but there was very little information on this.
So, I'll explain based on the results I got from my own experiments.
Performance Degradation
So, let's compare the performance of the CPU, file IO, and network IO tasks we previously checked, divided into a single thread pool vs. multiple thread pools.
for (int i = 0; i < taskCount; i++) {
final int taskId = i;
if (taskId % 3 == 0) {
futures.add(threadPool.submit(() ->
measureTaskLog("FileIO Task-" + taskId, taskId, () -> performIO(taskId))
));
} else if (taskId % 3 == 1) {
futures.add(threadPool.submit(() ->
measureTaskLog("NetworkIO Task-" + taskId, taskId, () -> performNetworkIO(taskId))
));
} else {
futures.add(threadPool.submit(() ->
measureTaskLog("CPU Task-" + taskId, taskId, () -> performCPU(taskId))
));
}
}I made it so that not just one type of task goes in, but they are distributed evenly.
(In multiple thread pools, it's not a unified threadPool, but rather networkPool, cpuPool, fileIOPool, etc.)
It's quite complex, so I'll test this not by direct measurement, but with what Java provides.
final long startTime = System.currentTimeMillis();
final long threadCpuStartTime = cpuTimeSupported ? threadMXBean.getCurrentThreadCpuTime() : -1;
performCPU(taskId);
final long endTime = System.currentTimeMillis();
final long threadCpuEndTime = cpuTimeSupported ? threadMXBean.getCurrentThreadCpuTime() : -1;
final long cpuTimeUsed = (threadCpuStartTime != -1 && threadCpuEndTime != -1)
? (threadCpuEndTime - threadCpuStartTime) / 1_000_000
: -1;final ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();threadMXBean is used to measure how much CPU time the current thread has received.
private static void saveDataToFile(final String filename, final List<TaskLog> logs) {
try (final BufferedWriter writer = new BufferedWriter(new FileWriter(filename))) {
writer.write("TaskID,Thread,Type,StartTime,EndTime,ExecutionTime,CPUTime(ms)
"); // CSV header
for (final TaskLog log : logs) {
writer.write(log.toCsv() + "
");
}
} catch (final IOException e) {
e.printStackTrace();
}
}Then, I'll write it to a CSV like this to compare.
First, let's look at multiple thread pools.
Multiple Thread Pools
Multiple Thread Pools Time Taken: 25811msSince it's in CSV format, it might be hard to read, so I'll just show a screenshot of the beginning.
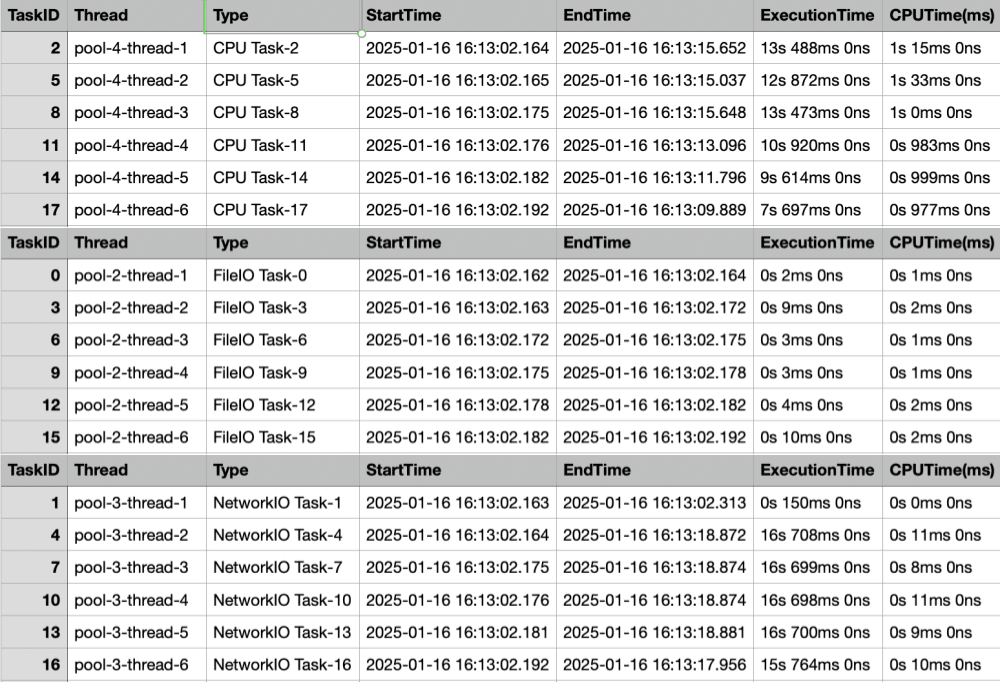
The thread pool receives tasks sequentially and assigns them to threads,
and you can see that CPU tasks also finish in a short amount of time. (You might think, "Isn't that taking a long time?", but you'll see differently below.)
It seems there's also a network issue with the network IO. 🥲
Single Thread Pool
Single Thread Pool Time Taken: 30783msThe execution time difference was about 5 seconds.
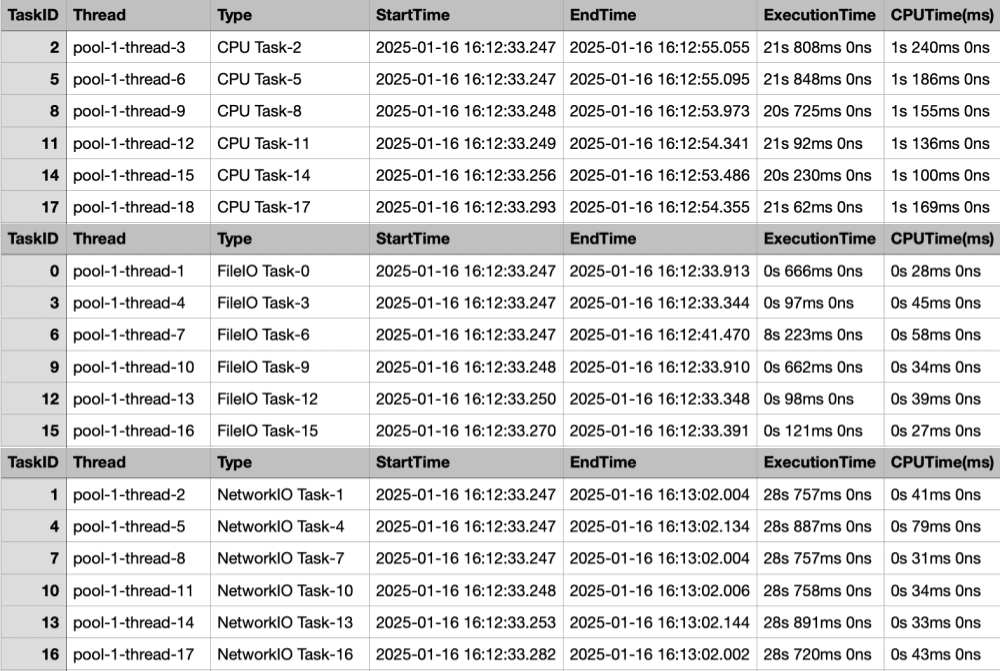
Each request takes a very long time from start to finish due to the multiple thread pools.
Considering the time it takes to perform the task + the time to get a time slot allocated on the CPU, it takes a really, really long time.
In-depth Analysis
With the help of GPT (actually, it just made a Map for me),
I'll measure:
- Average CPUTime by Task Type
- CPUTime Distribution by Task
- CPUTime Distribution by Thread
Multi-threaded
=== Average CPU Time by Task Type ===
Task Type: NetworkIO Task, Average CPU Time: 3.57 ms
Task Type: CPU Task, Average CPU Time: 1012.72 ms
Task Type: FileIO Task, Average CPU Time: 2.05 msTaskID: 248, Type: CPU Task, CPU Time: 1068 ms
TaskID: 119, Type: CPU Task, CPU Time: 1058 ms
TaskID: 242, Type: CPU Task, CPU Time: 1056 ms
TaskID: 53, Type: CPU Task, CPU Time: 1055 ms
...
TaskID: 125, Type: CPU Task, CPU Time: 951 ms
TaskID: 194, Type: CPU Task, CPU Time: 935 ms
TaskID: 4, Type: NetworkIO Task, CPU Time: 14 ms
TaskID: 7, Type: NetworkIO Task, CPU Time: 14 ms
TaskID: 22, Type: NetworkIO Task, CPU Time: 13 ms
TaskID: 43, Type: NetworkIO Task, CPU Time: 12 ms
TaskID: 199, Type: NetworkIO Task, CPU Time: 4 ms
TaskID: 283, Type: NetworkIO Task, CPU Time: 4 ms
TaskID: 30, Type: FileIO Task, CPU Time: 3 ms
TaskID: 36, Type: FileIO Task, CPU Time: 3 ms
TaskID: 42, Type: FileIO Task, CPU Time: 3 ms
TaskID: 45, Type: FileIO Task, CPU Time: 3 msThe max ~ min time for each task is also relatively uniform.
Single-threaded
=== Average CPU Time by Task Type ===
Task Type: NetworkIO Task, Average CPU Time: 26.60 ms
Task Type: CPU Task, Average CPU Time: 1049.45 ms
Task Type: FileIO Task, Average CPU Time: 3.28 msTaskID: 419, Type: CPU Task, CPU Time: 1172 ms
TaskID: 416, Type: CPU Task, CPU Time: 1169 ms
TaskID: 53, Type: CPU Task, CPU Time: 1162 ms
TaskID: 365, Type: CPU Task, CPU Time: 1151 ms
...
TaskID: 125, Type: CPU Task, CPU Time: 978 ms
TaskID: 497, Type: CPU Task, CPU Time: 958 ms
TaskID: 4, Type: NetworkIO Task, CPU Time: 185 ms
TaskID: 91, Type: NetworkIO Task, CPU Time: 82 ms
TaskID: 3, Type: FileIO Task, CPU Time: 42 ms
TaskID: 346, Type: NetworkIO Task, CPU Time: 40 ms
...
TaskID: 55, Type: NetworkIO Task, CPU Time: 14 ms
TaskID: 85, Type: NetworkIO Task, CPU Time: 14 ms
TaskID: 343, Type: NetworkIO Task, CPU Time: 14 ms
TaskID: 12, Type: FileIO Task, CPU Time: 13 ms
TaskID: 18, Type: FileIO Task, CPU Time: 13 msOn average, more time was spent than with multiple thread pools,
and you can see a large difference between the maximum and minimum times, especially for IO tasks.
(I think this is because a lot of CPU Context Switching occurs)
Task Mixing
Isn't it irrelevant since I/O doesn't receive CPU time?
However, the thread waits during that time.
If I/O-bound tasks and CPU-bound tasks are mixed, the threads performing I/O tasks will wait.
-> Even if a CPU-bound task is allocated a thread and only runs for 0.01 seconds, it has to wait until it's allocated.
=> As seen above, this can cause an OOM.
Possibility of Deadlock
This part is the same as a DB Connection Pool Deadlock.
Generally, it seems unlikely to be a problem since the number of threads in the pool is large, but it is possible.
ExecutorService executor = Executors.newFixedThreadPool(1);
try {
CompletableFuture<Void> parentFuture = CompletableFuture.runAsync(() -> {
CompletableFuture<Void> childFuture = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000); // simulate work
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}, executor);
childFuture.join(); // wait for child task to complete
}, executor);
parentFuture.join(); // wait for parent task to complete
} finally {
executor.shutdown();
}Or
ExecutorService executor = Executors.newFixedThreadPool(9);
for (int i = 0; i < 9; i++) {
final int parentId = i;
parentFutures[i] = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(500);
}
CompletableFuture<Void> childFuture = CompletableFuture.runAsync(() -> {
// rest is the same
...If a single piece of logic has a thread pool of 9, and you create 9 threads to do additional work?
pool-1-thread-6 - Parent Task 5 started
pool-1-thread-7 - Parent Task 6 started
pool-1-thread-8 - Parent Task 7 started
pool-1-thread-1 - Parent Task 0 started
pool-1-thread-2 - Parent Task 1 started
pool-1-thread-5 - Parent Task 4 started
pool-1-thread-3 - Parent Task 2 started
pool-1-thread-9 - Parent Task 8 started
pool-1-thread-4 - Parent Task 3 startedIt starts like this, and since there are no more threads, it gets into a deadlock state.
Conclusion
- First of all, there is a performance difference, period. - Eliminates interference by separating resources between tasks.
- IO occupies threads that need to be processed. - Other tasks keep waiting.
- There is a possibility of deadlock. - Tasks with dependencies on other tasks may have to wait continuously.
The key is to remember that you must get a task via getTask and be assigned a Worker thread for the O.S to allocate CPU time.
(A single thread pool gets congested because tasks are mixed.)
Analogy: Single Highway vs. Dedicated Lanes for Each Task - By GPT
- Single Thread Pool: A single highway where various types of vehicles (trucks, buses, motorcycles) travel together.
- If a truck (Network IO task) moves slowly, the vehicles behind it (CPU tasks) are delayed.
- Multiple Thread Pools: A highway with dedicated lanes for each type of task.
- Even if the truck goes slowly, CPU tasks are not affected and run independently in their own lanes.
The long post is over.
Let's strive to learn the C.S embedded in technology, not just the technology itself.
空